Claude Opus 4.7
Kehittyneimpien suurten kielimallien julkaisutahti on lyhentynyt vain pariin kuukauteen. Useimpien kehittäjien suosikkimalli Anthropicin Opus on päivittynyt versioon 4.7. Uusi malli ei paperilla ole erityisen iso harppaus, mutta tämä selkeästi näyttää nyt uunta suuntaa sekä Anthropicin asiakkaille että alalle yleisesti.
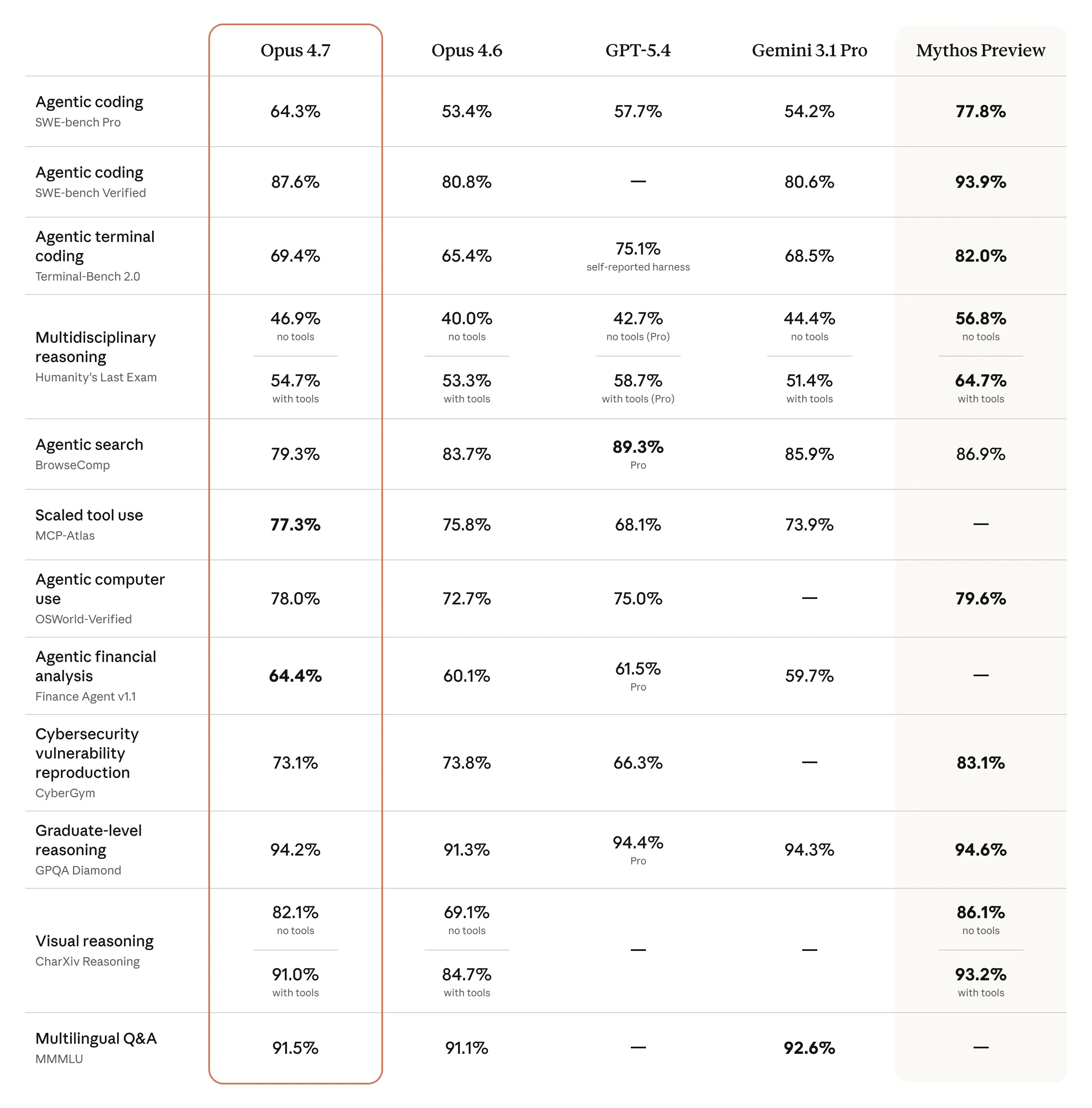
Pistepäivityksille tyypillisesti Opus on kehittynyt Anhropicin itse julkaisemien mittausten perusteella muutamia prosentteja lähes joka akselilla. Hinta on edelleen sama $5/$25 per miljoona tokenia ja konteksti-ikkunan koko on miljoona tokenia. Suurin muutos perustiedoissa on koulutusdatan päiväys, joka on hypännyt elokuulta tammikuulle 2026.
Anhropic on ollut tasapainoillut hankalasta tilanteesta toiseen oikeastaan koko kevään ajan. Viime viikkoina yritys on ollut jatkuvassa SOME-myllerryksessä kehittäjien kanssa, jotka ovat kipuilleet kuukausisopimukseen tehdyistä päivityksistä jotka tiukensivat käyttörajoja. Anthropic on joutunut myös toistuvasti torjumaan lähinnä henkilökohtaisiin anekdootteihin perustuvia syytöksiä mallien tietoisesta tyhmentämisestä. Lisäksi yhtiön suurin lypsylehmä Claude Code on saanut merkittävää kilpailua sekä OpenAI:n Codexin, että OpenCoden ja pienempien työkalujen kuten Pi:n taholta. Tilannetta ei ole auttanut yhtään se, että Anthropicin palveluiden saavutettavuus on tippunut niin surkeaksi, että uptime-prosentti on laskenut välillä alle yhdeksänkymmenen (kun monet suositut palvelut ovat saatavilla “viisi yhdeksää” ajasta, eli 99,999%).
Uuden Opuksen mukana tulee liuta ei-niin mairittelevia muutoksia. Käyttäjille ikävimpänä lienee uusi tokenisaattori, joka tekee uuden mallin käytöstä noin kolmanneksen edeltäjäänsä kalliimpaa, koska tokeneja kuluu nyt enemmän. Anhropicin mukaan Claude Coden käyttäjien rajoituksia on nostettu vastaavasti. Omaan nenääni tämä haiskahtaa enemmän rahastukselta. Claude Code puolestaan ei enää näytä lainkaan ajattelutekstejä (jotka Anthropic jo aiemmin tiivisti referaateiksi vakoiluun vedoten), joten mallin päättely on nyt täysin pimennossa käyttäjältä oletuksena. Ajattelun voi ainakin vielä toistaiseksi palauttaa näkyviin käynnistämällä Claude Coden vivulla --thinking-display summarized.
Kolmas potentiaalisesti huolestuttava muutos uuden 4.7-mallin ominaisuuksiin on tiukennettu systeemiprompti tietoturvaan liittyvien asioiden tutkimiseen. “Kuka ajattelisi lapsia”-tyyliseen ajattelumalliin vedoten Anthropic “auttaa” käyttäjiä tiukentamalla sääntöjä siitä millaisiin kysymyksiin uusi Opus saa vastata. Asiasta jotain ymmärtävät käyttäjät ovat luonnollisesti vähän käärmeissään, koska parempi strategia parempaan tietoturvaan olisi päin vastoin auttaa käyttäjiä rakentamaan turvallisempaa softaa (minkä oleellisena osana on esimerkiksi kaikenlaisten tietoturva-analyysien ja -testauksen tekeminen). Tässä vaiheessa huoli on ehkä hienoisesti akateeminen kun kenelläkään ei ole vielä juurikaan käytännön kokemusta uusien sääntöjen vaikutuksesta, mutta kehityssuunta on joka tapauksessa huono.
Omat filikset uudesta Opuksesta ovat jollain tavalla haikeita. Kun kuukausimaksullinen palvelu on nyt sidottu yksinomaan Claude Codeen eikä omia työkaluja saa enää käyttää, kaikkien Anthropicin mallien hyödyllisyys henkilökohtaisessa käytössä on romahtanut. Käyttörajojen tiukennukseen yhdistettyjä Opuksesta on nyt tulossa malli jota kannattaa käyttää enää hyvin rajatussa työssä vaihtoehtoihin nähden. Toivon kovasti, että Anthropic pysyy kilpailussa vahvasti mukana, koska tämä juna ei ole pysähtymässä ihan hetkeen, ja vaihtoehdot ovat toinen toistaan (tavalla tai toisella) huonompia.
Tuunaa Claude Code
Jos haluat tuunata Claude Coden käyttämään vähemmän tokeneja ja toimimaan ylipäätään vähän paremmin, tuunaa asetuksiin (~/.claude/settings.json) seuraavat:
"env": {
"CLAUDE_CODE_DISABLE_1M_CONTEXT": "1",
"CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING": "1",
"CLAUDE_CODE_DISABLE_AUTO_MEMORY": "1",
},
"awaySummaryEnabled": falseCLAUDE_CODE_DISABLE_1M_CONTEXT: jos et tarvitse miljoonan tokenin kallista (ja laadullisesti arvelluttavaa) kontekstia, kytke se pois.CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING: rajaa mallin ajattelun arvoonMAX_THINKING_TOKENS, mikä useimmissa tilanteissa vähentää tokenien kulutusta (ajattelusta tinkimällä). Huom! Tämä asetus ei toimi uuden Opus 4.7-mallin kanssa. (Mutta muut mallit kunnioittaat edelleen.)CLAUDE_CODE_DISABLE_AUTO_MEMORY: Clauden muisti on vähän kyseenalainen ominaisuus. Ellet koe että siitä on hyötyä, kytke tämä asetus päälle ja säästät taas tokeneja. Kannattaa tehtä erityisesti sellaisissa projekteissa joissa on hyväCLAUDE.mdja/tai muuta opastusta LLM-agenteille.awaySummaryEnabled: “kolmetoista sekuntia sitten teit muun muassa tätä” syö tokeneitasi Täysin Turhaan- EKSTRA:
CLAUDE_CODE_SUBAGENT_MODEL: mikäli teet asioita joissa käytät paljon aliagentteja, kannattaa testata toimiiko"sonnet"parempi kuin oletusarvo"haiku". Joissain töissä Haiku palauttaa yksinkertaisesti täysin ala-arvoista roskaa, mikä taas johtaa siihen että päämallin konteksti myrkyttyy. Jos haluat pelata varman päälle, kiellä mallia käyttämästä subagentteja tai vaihda oletusagentiksi Sonnet. (Itse en käytä tätä koska yleensä kiellän käyttämästä näitä, tai jos tiedän että niistä on hyötyä, oletan että Haiku osaa hommansa. YMMV!)
“Piirrä svg-kuva trailerilla olevasta veneestä”
(Anthropic muutti rajapinnan päättelymäärän muotoa, jota useimmat työkalut eivät tätä kirjoitettaessa vielä osanneet käyttää oikein. Alaolevat –lievästi mitäänsanomattomat– kuvat on luotu aiempaa maksimipäättelyä käyttäen OpenRouterin rajapinnan kautta.)

Vaikeampi versio 2:
Piirrä svg-kuva trailerilla olevasta veneestä. Traileri tulee olla kuvattuna sivusta, vetoakseli oikealla. Kuvassa pitää näkyä yksinkertainen moottorivene, perämoottori, veneen tuulilasi, sekä trailerin sivutuet.










